最近這段時間差不多把 DDIA 讀過一輪,不過老實說對前面幾個章節的印象也比較模糊了XD,加上近期會參與 System Design Interview 的讀書會,初步看起來 System Design Interview 比起 DDIA 講的內容淺很多,不過還是想說把這個當成一個契機,多做幾章讀書筆記來加深與內化一下 DDIA 前幾章介紹的內容。
本文的圖片和程式碼都來自原書內容。
Data Structures That Power Your Database
為什麼身為 application developer 的我們會需要了解 database 底下的機制呢?
- We need to select a storage engine that is appropriate for application.
- In order to tune a storage engine to perform well on our kind of workload, we need to have a rough idea of what the storage engine is doing under the hood.
我們從最簡單的範例開始,以下面兩個 bash function 實作一個非常簡易的 key-value store:
1 |
|
簡單分析這兩隻 function:
- db_set: append-only log,也是很多 database 的儲存方式, 效率佳。
- db_get: 效率為 O(n),並不理想。
為了改善 db_get 的效率,我們可以會需要一些額外的 metadata 來輔助尋找 record,即 index。Index 並不影響儲存的內容,但能改善 read queries 效能,不過代價是會影響到 write queries,因此身為開發者需要 application 的 query patterns 來決定要建立哪些 index。
Hash Indexes
已一個 key-value store 為例,如果要改善 read queries 效能,很直覺的能想到去維護一個 key to byte offset 的 hash map,範例與說明如下:
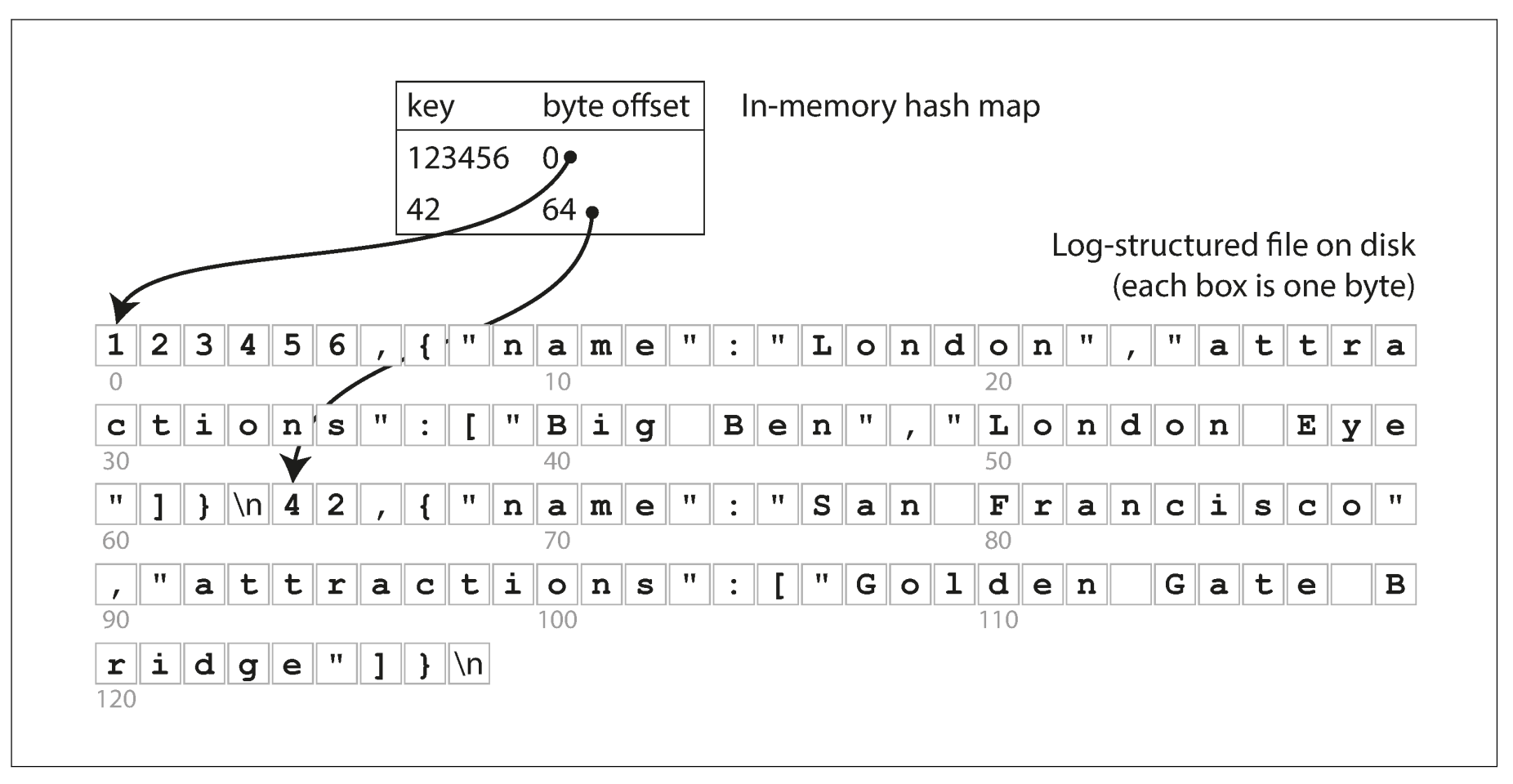
- Insert/Update: 更新 hash map (in-memory),並將 key-value append 至 log-structured file (DIsk) ,越近的 record 越優先 。
- Get: 先透過 hash map 拿到 offset,再來就能透過一個 disk seek 或從 filesystem cache 中拿到資料。
- 適用於 key 數量不多 (需要 in-memory map),但需要頻繁更新 value 的 workload。
- 此即 Bitcask 的實作方式。
另外,為了避免一個 log file 無限增長,可以將其分成多個 segment,寫滿一個就開始下一個,每個 segment 維護一個上述的 hash map,get data 時則由近而遠查詢 key 有沒有在 map 裡。這種作法的好處是可以設計一個 background task 對每個 segment 進行 compaction,以及將 compacted segments 再次 merge 合為新的 segment,並且只要讓 client 的 read/write queries 對 old segments 操作即可不受此 background task 影響,其實作上有一些考量:
- File format: binary fomrat is better.
- Handle Deletion: add tombstone (deletion) record.
- Crash recovery: taking snapshot of each segment’s hash map avoid the mapping restore process from loading the entire segments.
- Data corruption: data checksum to detect corruption.
- Concurrency: one-writer thread for append-only file; read concurrently by multiple threads.
至此我們可以了解用這種 append-only logs 實作 data store 的好處:
- Sequential writes are much faster than random writes.
- Easier concurrency control and crash recovery.
- Merging old segments avoids file fragmentation.
但同時也有 hash table 的大小需要 fit in memory,以及 range query 效率差等限制。
SSTables and LSM-Trees
前述方式的每個 segment 中,由於是 append-only,key-value pairs 的排序只和寫入的時間有關。SSTable (Sorted String Table) 則不然,會將 key-value pairs 以 key 來進行排序,每個 key 是唯一的,並且在經過 compaction 的 merged segment 中也會維持相同特性。SSTable 與前述的 log segments with hash indexes 比起來好處如下:
- Easier compaction and merge (with sorted segments), even if the files are bigger than available memory.
- Since it’s sorted, no longer need to keep all the keys with offset in memory: sparse index in memory is enough to get the offset (based on existed indexes + scan).
至於 SSTable 的建構與維護,可以參考以下流程:
- Maintain a sorted structure in memory, called memtable (while on disk in possible like B-Trees, in-memory is easier).
- Simply add the written record to the memtable.
- When the memtable is bigger than threshold (few MB), write it out to disk as a SSTable file. (In the SSTable file, the key-value pairs are also sorted)
- To serve a read request, find the key in the following order: memtable, most recent on-disk segment, then the next-older one, etc.
- Run a merging and compaction process in the background to combine segment files from time to time.
上述方式有一個顯著的缺點:在 process crash 時會丟失 memtable 中的 records。可以額外維護一個和前一小節一樣的 append-only log file on disk,作為 crash 之後 recovery 的依據,並且只要 memtable flush 到 disk 後,該 log file 就可以移除。
這樣的 indexing structure 在早期也可以被稱為 LSM-Tree (Log-structued Merge-Tree),因此 LSM storage engine 即是基於 SSTable 概念實作,如 LevelDB, RocksDB,Cassandra 和 HBase 中也有用到類似的 Storage engine,Lucene 也是用類似方式存 term dictionary (key: a word, value: posting list containing the word)。
另外,SSTables 的 compaction 和 merging 的策略主要有兩種:
- sized-tiered
- Newer, smaller SSTables are merged into older, larger SSTables.
- HBase, Cassandra.
- leveled-tiered:
- Split key range into smaller SSTables, older data is moved into separate levels.
- Less disk space is necessary.
- LevelDB, RocksDB, Cassandra.
LSM-tree 也有效能較差的 Case,例如搜尋不存在的 key 仍需找遍 memtable 和所有 segment files,這部分可以用 Bloom filters 改善 (可能 false positive,但不可能 false negative,換言之 true 表示可能存在,false 表示絕不存在),不過優點也不少:
- 大小不限於 RAM。
- 由於存的是 sorted data,range query 的效能很好。
- sequential dIsk write,write throughput 高。
B-Trees
長久以來最為廣泛使用的 index,可稱為 standard index implementation,其特性如下:
和 SSTables 相同,會保持 key-value pairs sorted,因此尋找特定 key 還有 range query 的效能良好。
儲存單位的 page 是固定大小的 block (通常是 4KB),這和大小不定的 segment 非常不同,其結構可以參考下圖:
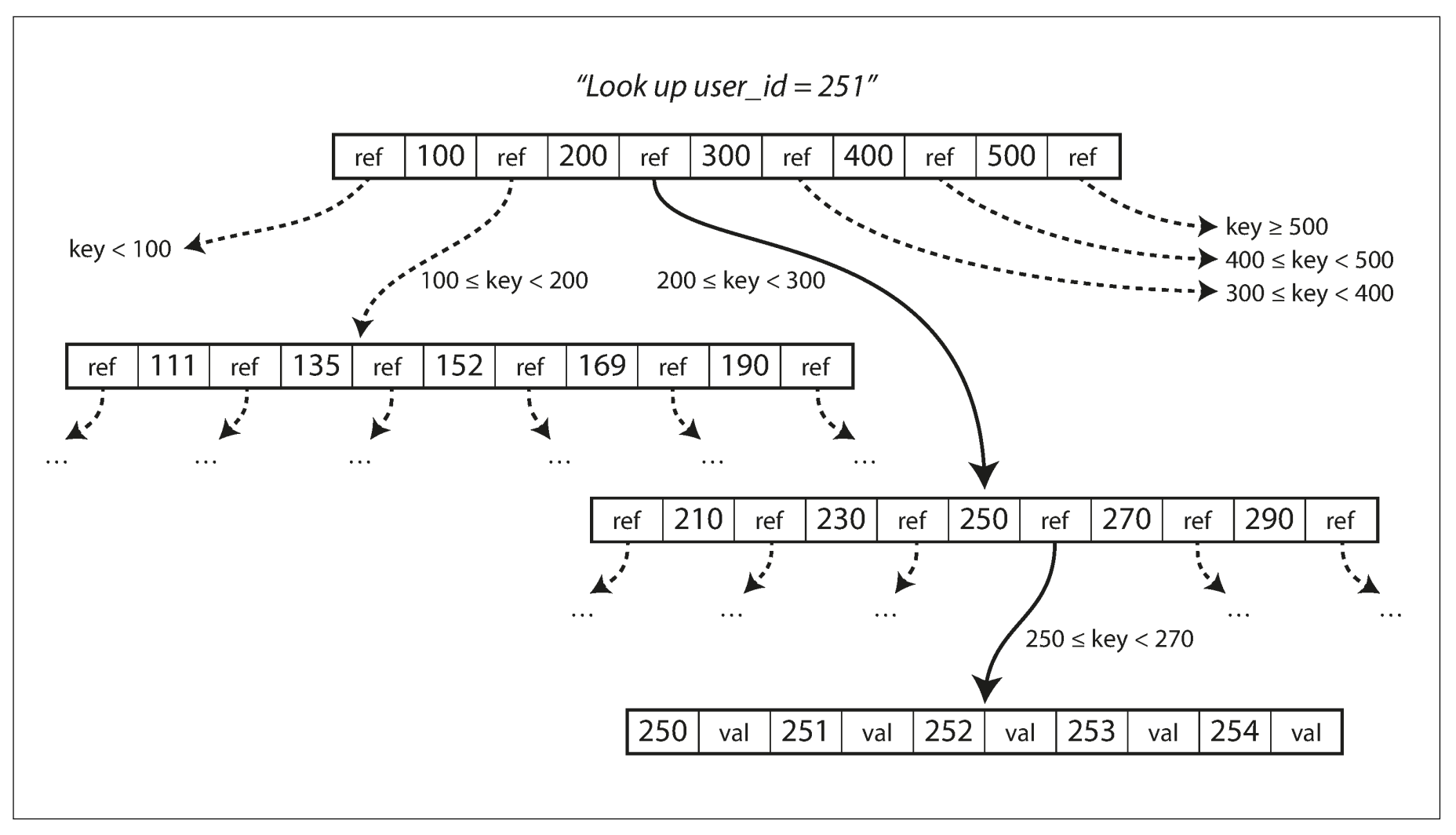
參考上圖,B-tree 中的每個 page 都有多個 key (boundary),在非 leaf 的 page 中 key 對應到的是 child page 的 reference (pointer),而 leaf page 則會對應其 value。因此尋找某個 key 的流程會是:
- 從 root page 出發。
- 根據 page 中的 Key boundaries 遞迴尋找 child page。
- 直到找到 leaf page。
Read/Write 都是以類似的邏輯運行,惟 write 時如果 page 的空間不足,此時會將此 page 分為兩個 half-full pages,並更新 parent page 的 key ranges。
而每個 page 擁有的 child page reference 數量即為 Branching factor,實務上 4KB 的大小通常為數百。雖然 B-tree 和其他平衡樹的 time complexity 都是 O(log n),但只要 branching factor 夠大,即使樹的層數不多也能儲存很大量的資料 (A four-level B-tree with 4KB pages and branching factor 500 can store up to 256TB)。
B-tree 會更新 page file,這和前面介紹的 LSM-trees 等 append-only log-structured 結構非常不同,這會引發以下問題:
- 如果操作涉及多個 pages (如 split 需要產生兩個新 pages、更新 parent page),可能會因為斷電等異常導致只有部分完成,造成 index corruption。解法通常是額外存紀錄改動的 append-only log files (WAL, redo log),用來做之後的 crash recovery。
- 多個 thread 同時 access 需要注意 concurrency control,通常會用 latches (lightweight locks) 來保護。前述 log-structed 的方式由於 merging 是 background task 對 old segments 進行,不會干擾到 incoming queries 操作的 segment。
由於 B-tree 的廣為使用,因此有很多研究出很多最佳化的方式,例如:
- copy-on-write scheme: Instead of overwiting pages and maintaining a WAL, pages can be stored in multiple different versions, which is also useful for concurrency control.
- Abbreviating the key to increase branching factor.
- Maintain the leaf pages in sequential order to speed up (difficult when the tree grows).
- Additional pointers such as sibling to avoid jumping back to parent pages while scanning.
- Variants as fractal trees borrow some log-structured ideas to reduce disk seeks.
B-Trees vs LSM-Trees
大致介紹完幾種加速 database 的儲存結構,在這個小節詳細比較在前兩個小節介紹的 B-trees 和 LSM-trees。
LSM-Trees
- Typically are faster for writes and slower for reads (while benchmarks are often inconclusive and sensitive to details of the workload).
- Can sustain higher write throughput beacause of:
- lower Write-amplification (SSDs concern a lot since their blocks can only be overwritten a limited number of times before wearing out).
- Sequential write (especially important on magnetic hard drives).
- Fragmentation can be removed therefore can be compressed better (in B-trees page some space remains unused).
- Lower write amplification and reduced fragmentation allow more read and write requests within the available I/O bandwidth.
- Sometimes compaction cannot keep up with the rate of incoming writes
B-Trees
Generally more mature.
Typically are faster for reads and slower for write (while benchmarks are often inconclusive and sensitive to details of the workload).
Predictable performance compared with LSM-trees which somtimes affected by compaction process.
Each key exists in exactly one place in the index. This aspect make it easier to implement transaction isolation using locks.
總結而言兩者的好壞並不絕對,每個 storage engine use case 也不同,值得實測比較來決定哪種較為適合。
Other Indexing Structures
上述的討論的 key-value indexes 類似平常 table 中的 primary key index,與 secondary indexes 的差別在於每個 key 都是獨特的,後者單純是用來加速查詢。另外還有 clustered index, covering index 這些 index 本身除了 reference 之外還有存 row data 的類型,大概比較起來就是用 data duplication (write overhead) 來換 read 效能。
至於 multi-column indexes,有較常見但限制較多的 concatenated index,以及靈活度較高的 multi-dimensional indexes,後者常用於多維資料的查詢,通常用類似 R-trees 的資料結構建構。
後續還有簡介 full-text search, fuzzy indexes 等類型,以及介紹 in-memory database:由於 RAM 日漸便宜,因此越來越多這類型的 database 被開發,其特性如下:
- Some only intended for caching use only (e.g. Memcached).
- Some aims for durability, which can be achieved with special hardware (such as battery-powered RAM), by writing log of changes/snapshot to disk, or by replicating the in-memory state to other machines (need to reload data after a restart).
- Better performance:
- They don’t need to read from disk.
- Avoid the overheads of encoding in-memory data structures in a form that can be written to disk.
- Because it keeps all data in memory, its implementation is compara‐ tively simple
- anti-caching: support datasets larger than the available memory by evicting individual records rather than entire memory page to disk (similar to what OS do with vm and swap).
- non-volatile memory (NVM) technologies is a new area of research.
Transaction Processing or Analytics
這個章節後續介紹的 OLTP vs OLAP, data warehouse, ETL, star/snowflake/multi-dimensional schema 等觀念,與更好支援 OLAP 的 storage solution: column-oriented storage。這些知識對我來說都算蠻新鮮的,不過畢竟平常工作接觸的還是 user-facing 的 OLTP,因此這部分決定就先讀過,未來真的有遇到再來整理筆記,也能順便複習。